AWS-Based Data Analysis Architecture
Amazon Web Services (AWS) is a secure cloud services platform offering cloud computing, database storage, content delivery, and other functionality. In addition to hosting data, AWS offers customers data analysis tools and insight to help them boost the customer’s digital experience and offerings.
Application programming interfaces (APIs) allow applications to connect with and exchange information with other applications. Amazon API Gateway allows developers to create, distribute, monitor, and secure APIs at any scale. Amazon API Gateway provides easy and efficient API development, cost-effectiveness, flexible security controls by integrating normally separate API development steps into a single process
AWS Lambda lets you forget about servers. Instead of leasing server space and running your applications and services on those servers, AWS runs the servers and you pay for computational time used on those servers. Lambda allows businesses to run code for any possible app or service on a reliable server without needing to run the server themselves. Continuous scaling and consistent performance are among the major benefits you’ll get.
Amazon CloudWatch provides real-time monitoring of cloud computing resources for AWS customers. With this tool, developers, engineers, and IT managers can monitor their apps, respond to performance changes immediately, optimize apps, and get a unified picture of operational health. In a nutshell, users can observe data across AWS resources, derive actionable insights, and enhance operational performance.
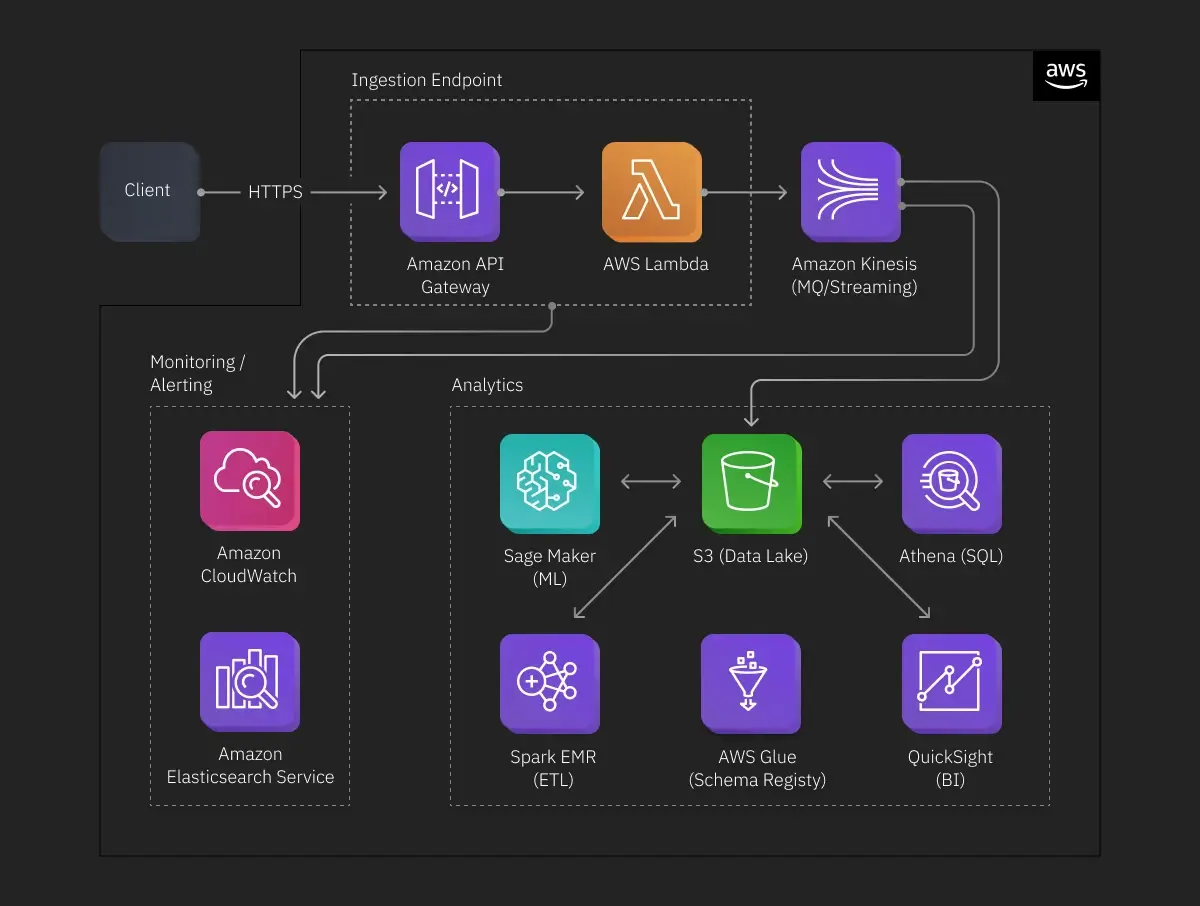
The table above reflects AWS-based system architecture and its components. Rather than speaking about each of them, let’s take a look at how data flows step-by-step:
- The localized application client (mobile/desktop) reports the metrics to the data platform over a public network (secure protocol like HTTPS).
- The data goes through the API gateway and a load balancer and then reaches a cluster of data ingestion services (custom REST API or AWS Lambda).
- The data ingestion service authenticates the data source, validates the data, and sends the data into a queue to be processed by Kafka or AWS Kinesis.
- Kafka Streams or AWS Kinesis processes (filters, aggregates, etc.) the incoming data (by).
- After processing, the data is inserted into a data lake (AWS S3 or other object storage) in a raw format or a format suitable for efficient processing (columnar format like ORC / Parquet).
- The ETL and all of the remaining data analysis/processing is done using Spark / Hive (managed by AWS EMR), and the results are re-inserted into the data lake. Apache Airflow handles job orchestration (dependency management, failure recovery, scheduling).
- Internal users (analysts) are then able to use a BI tool (AWS QuickSight, Apache Superset, Tableau) to gain insights into the data.
- Engineers/analysts can also run SQL queries using Presto (standalone or managed by AWS Athena), possibly persisting results back into the data lake.
- The data lake is also the source of the raw and pre-processed data for advanced (predictive/prescriptive) analytics using statistical, data science, or machine learning tools.
- The schema of the data is persisted in the central schema registry (AWS Glue).
- All the components/services expose metrics and logs for persistence by the monitoring/alerting cluster. The monitoring/alerting cluster diagnoses potential issues (software bugs/hardware failures), monitors the health of the system, and alerts developers and stakeholders of any problems.
Cloud-Agnostic Data Analytics Architecture
Cloud-agnostic architecture refers to tools, services, and apps created for operation on two or more cloud platforms.
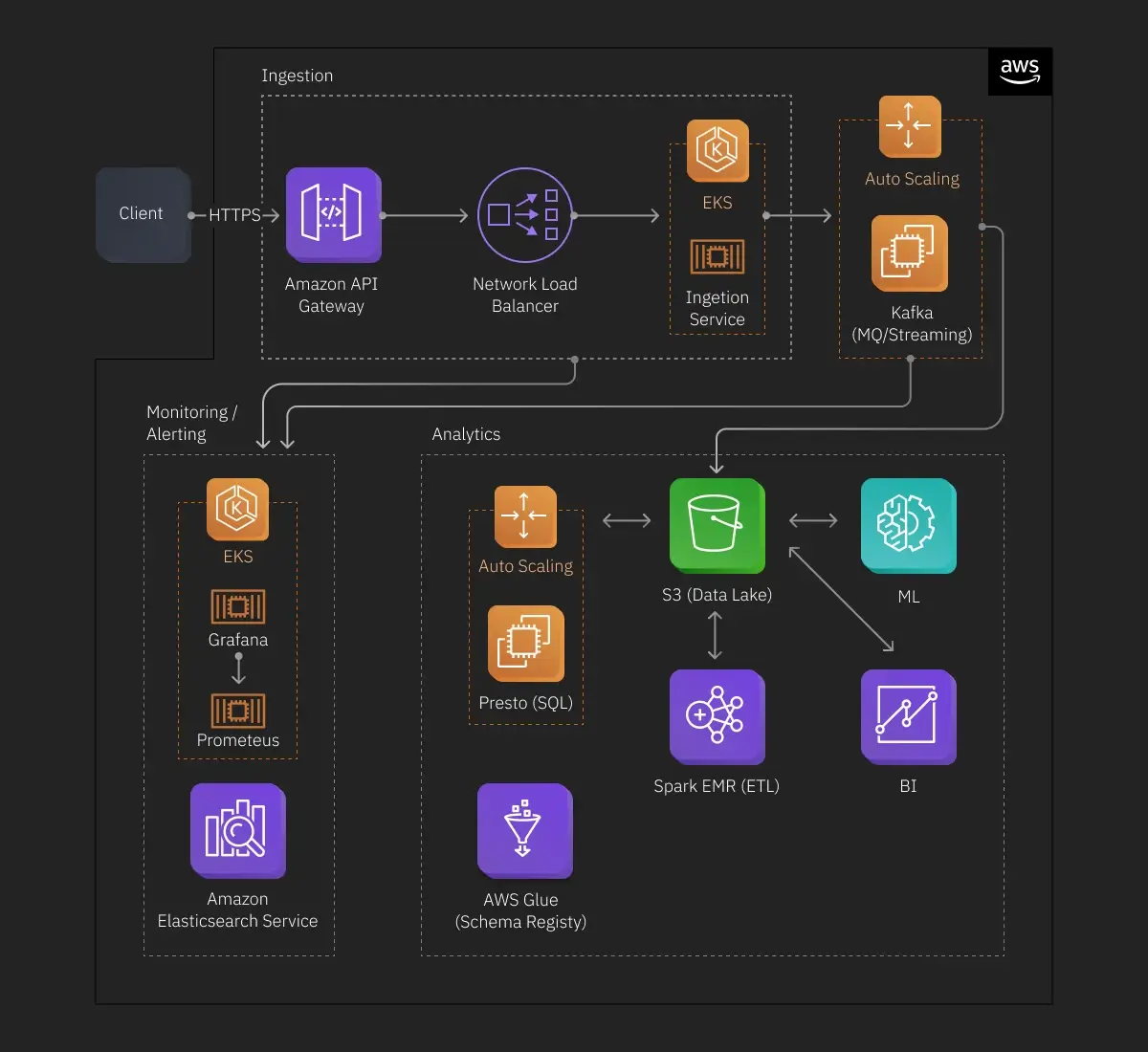
Of course, cloud agnosticism has its own pros and cons.
Pros:
- Flexibility
- Reliability
- Vendor lock-in avoidance
Cons:
- Vendor lock-out
- Complexity
- Costs
Cloud-agnostic solutions are solutions independent of a specific cloud provider. Depending on your needs, it may be cheaper or easier to use a 3rd-party vendor to host cloud operations or set up cloud operations on another major cloud platform. When you install cloud operations on Azure you can only work with the services Azure offers. But when you have a cloud-agnostic solution, you can deploy it on any cloud provider and move it between cloud providers if needed.
The choice to use cloud-agnostic solutions versus cloud-native solutions (such as AWS and MS Azure) depends on the specific business objectives of an organization. The current trend in data analytics is to migrate from cloud-native to cloud-agnostic to give teams, developers, and budgeting more flexibility.
“We’re cloud-agnostic. We said we will tackle the most stubborn, old-fashioned industries that think they can’t innovate because of legacy systems or mainframes that are decades old. Everyone is bringing their assets to the cloud, and we can accelerate that by allowing companies to shut off data center assets more quickly.”
— Alex Schmelkin, Chief Marketing Officer, Unqork
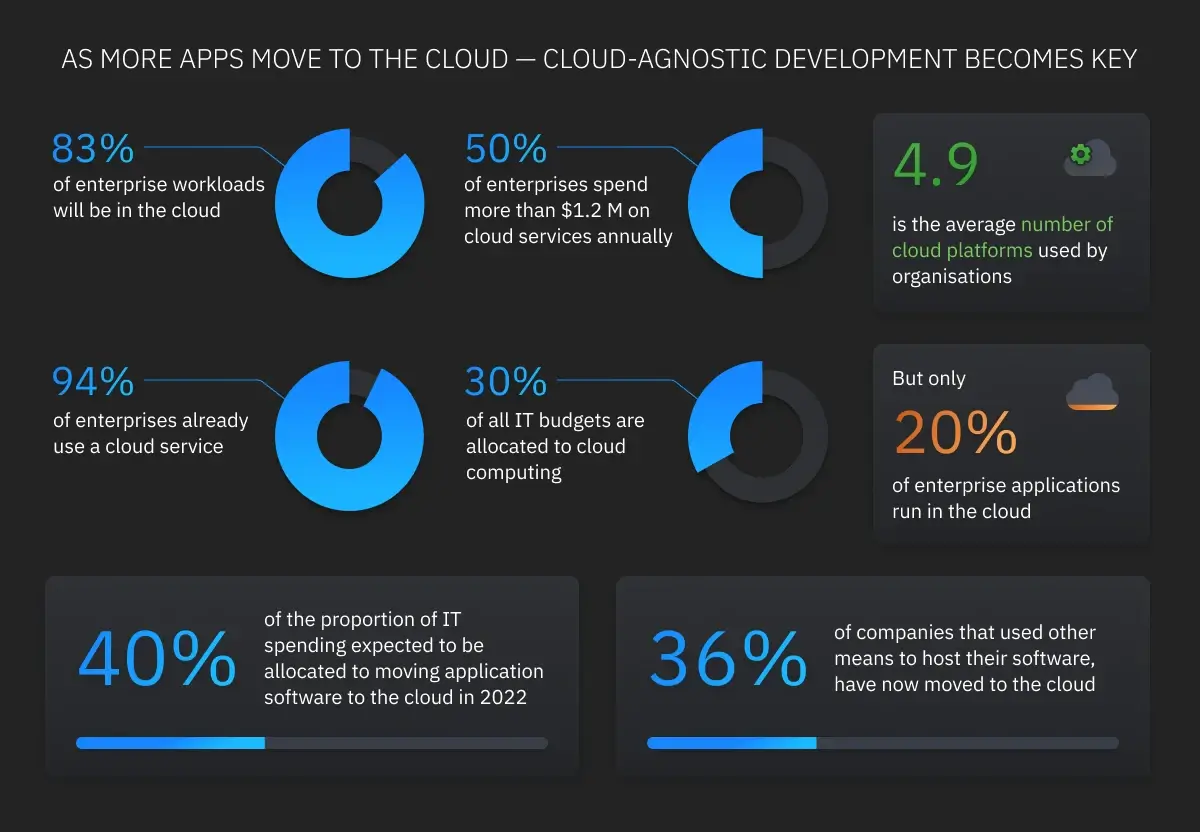
Let’s compare AWS-based architecture and cloud-agnostic architecture on several metrics: time to market, support cost, infrastructure cost, and vendor lock-in.

Conclusion
Overall, AWS-based data analysis architecture is better for companies that need to process smaller amounts of data and get the product out of the door as soon as possible. Cloud-agnostic architecture is better for companies that need to process large amounts of data while containing infrastructure costs. Cloud-agnostic architecture allows for cost optimization and risk hedging by making use of multi-cloud or hybrid cloud architectures.
IMVU Case Study: Improving The Data Platform

About the company. IMVU Inc., is an online metaverse and social game. IMVU members use 3D avatars to meet new people, chat, create, and play games. IMVU hosts 6M+ active players, and a virtual goods catalog of more than 40 million items, the largest catalog of virtual items in any game platform. The number of concurrent users reached 150,000 in April 2020.
A Proxet team has been working on architectural and engineering improvements to IMVU’s data platform, as well as a cloud migration project (converting from IMVU’s bare-metal data center to AWS).
Architecture Design
Business Objectives Achievements
- Implemented a scalable data platform to accommodate the continuous growth of the data volume.
- Re-architected data ingestion to minimize data loss and achieve reliable delivery for >99.9% of data.
- Improved data quality and implement advanced checks and validation.
- Implemented data analysis architecture that is scalable, available, consistent, fault-tolerant, and cost-effective.
Data Sources
- UI events – events that are triggered by user interactions
- Data events – events that occur in response to database changes (update/insert/delete), such as changes in account data
- Service events – events that are triggered by internal services
Data format: mostly JSON.
Daily volume: ~0.75 Tb.
Technology Stack
- Ingestion services: Java 11 / Scala 2.13
- Cluster orchestration: Kubernetes (Amazon EKS)
- Data lake: Amazon S3 / EMRFS
- Data formats: JSON (raw data), ORC / Parquet (in the data lake)
- Message queue: Apache Kafka
- Monitoring / alerting:
- Prometheus (time series database / alerting)
- Grafana (visualization)
- Elastic stack (log ingestion / processing / visualization)
- Job orchestration / scheduling: Apache Airflow
- ETL: Apache Spark / Hive (Apache EMR)
- SQL engine: Presto
- BI: Tableau
Performance
Time between data submission (by client) and persistence in the data lake: <5 minutes.
Time to run a daily set of reports (~300 ETL jobs): ~8 hours.
Cost
- EMR: $3,000/month
- S3: $15,000/month
- EC2: $5,000/month
- Other (data transfer, development tools, etc.): $7,000/month
- Total AWS spend: $30,000/month
Team Structure
- 5 Data Engineers
- 4 Data Analysts
- 2 DevOps
- 1 Data Architect
- 1 Director of Data Engineering
The Proxet team successfully delivered a scalable infrastructure for data streaming and data analytics. This new framework allows IMVU to benefit from the huge amounts of user-generated data available to the company. At any time, IMVU’s analysts can access real-time information on user behavioral and usage patterns, and generate reports on these patterns.